Reg.ru: домены и хостинг
Крупнейший регистратор и хостинг-провайдер в России.
Более 2 миллионов доменных имен на обслуживании.
Продвижение, почта для домена, решения для бизнеса.
Более 700 тыс. клиентов по всему миру уже сделали свой выбор.
*Наведите курсор мыши для приостановки прокрутки.
Назад Вперед
Кодировки: полезная информация и краткая ретроспектива
Данную статью я решил написать как небольшой обзор, касающийся вопроса кодировок.
Мы разберемся, что такое вообще кодировка и немного коснемся истории того, как они появились в принципе.
Мы поговорим о некоторых их особенностях а также рассмотрим моменты, позволяющие нам работать с кодировками более осознанно и избегать появления на сайте так называемых кракозябров , т.е. нечитаемых символов.
Итак, поехали...
Что такое кодировка?
Упрощенно говоря, кодировка - это таблица сопоставлений символов, которые мы можем видеть на экране, определенным числовым кодам.
Т.е. каждый символ, который мы вводим с клавиатуры, либо видим на экране монитора, закодирован определенной последовательностью битов (нулей и единиц). 8 бит, как вы, наверное, знаете, равны 1 байту информации, но об этом чуть позже.
Внешний вид самих символов определяется файлами шрифтов , которые установлены на вашем компьютере. Поэтому процесс вывода на экран текста можно описать как постоянное сопоставление последовательностей нулей и единиц каким-то конкретным символам, входящим в состав шрифта.
Прародителем всех современных кодировок можно считать ASCII .
Эта аббревиатура расшифровывается как American Standard Code for Information Interchange (американская стандартная кодировочная таблица для печатных символов и некоторых специальных кодов).
Это однобайтовая кодировка , в которую изначально заложено всего 128 символов: буквы латинского алфавита, арабские цифры и т.д.

Позже она была расширена (изначально она не использовала все 8 бит), поэтому появилась возможность использовать уже не 128, а 256 (2 в 8 степени) различных символов, которые можно закодировать в одном байте информации.
Такое усовершенствование позволило добавлять в ASCII символы национальных языков , помимо уже существующей латиницы.
Вариантов расширенной кодировки ASCII существует очень много по причине того, что языков в мире тоже немало. Думаю, что многие из вас слышали о такой кодировке, как KOI8-R - это тоже расширенная кодировка ASCII , предназначенная для работы с символами русского языка.
Следующим шагом в развитии кодировок можно считать появление так называемых ANSI-кодировок .
По сути это были те же расширенные версии ASCII , однако из них были удалены различные псевдографические элементы и добавлены символы типографики, для которых ранее не хватало "свободных мест".
Примером такой ANSI-кодировки является всем известная Windows-1251 . Помимо типографических символов, в эту кодировку также были включены буквы алфавитов языков, близких к русскому (украинский, белорусский, сербский, македонский и болгарский).
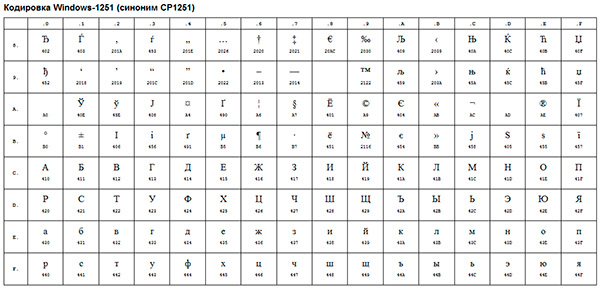
ANSI-кодировка - это собирательное название . В действительности, реальная кодировка при использовании ANSI будет определяться тем, что указано в реестре вашей операционной системы Windows. В случае с русским языком это будет Windows-1251, однако, для других языков это будет другая разновидность ANSI.
Как вы понимаете, куча кодировок и отсутствие единого стандарта до добра не довели, что и стало причиной частых встреч с так называемыми кракозябрами - нечитаемым бессмысленным набором символов.
Причина их появления проста - это попытка отобразить символы, закодированные с помощью одной кодировочной таблицы, используя другую кодировочную таблицу .
В контексте веб-разработки, мы можем столкнуться с кракозябрами, когда, к примеру, русский текст по ошибке сохраняется не в той кодировке, которая используется на сервере .
Разумеется, это не единственный случай, когда мы можем получить нечитаемый текст - вариантов тут масса, особенно, если учесть, что есть еще база данных, в которой информация также хранится в определенной кодировке, есть сопоставление соединения с базой данных и т.д.
Возникновение всех этих проблем послужило стимулом для создания чего-то нового. Это должна была быть кодировка, которая могла бы кодировать любой язык в мире (ведь с помощью однобайтовых кодировок при всем желании нельзя описать все символы, скажем, китайского языка, где их явно больше, чем 256), любые дополнительные спецсимволы и типографику.
Одним словом, нужно было создать универсальную кодировку, которая решила бы проблему кракозябров раз и навсегда .
Юникод - универсальная кодировка текста (UTF-32, UTF-16 и UTF-8)
Сам стандарт был предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (Unicode Consortium, Unicode Inc.), и первым результатом его работы стало создание кодировки UTF-32 .
Кстати, сама аббревиатура UTF расшифровывается как Unicode Transformation Format (Формат Преобразования Юникод).
В этой кодировке для кодирования одного символа предполагалось использовать аж 32 бита , т.е. 4 байта информации. Если сравнивать это число с однобайтовыми кодировками, то мы придем к простому выводу: для кодирования 1 символа в этой универсальной кодировке нужно в 4 раза больше битов , что "утяжеляет" файл в 4 раза.
Очевидно также, что количество символов, которое потенциально могло быть описано с помощью данной кодировки, превышает все разумные пределы и технически ограничено числом, равным 2 в 32 степени. Понятно, что это был явный перебор и расточительство с точки зрения веса файлов, поэтому данная кодировка не получила распространения.
На смену ей пришла новая разработка - UTF-16 .
Как очевидно из названия, в этой кодировке один символ кодируют уже не 32 бита, а только 16 (т.е. 2 байта). Очевидно, это делает любой символ вдвое "легче", чем в UTF-32, однако и вдвое "тяжелее" любого символа, закодированного с помощью однобайтовой кодировки.
Количество символов, доступное для кодирования в UTF-16 равно, как минимум, 2 в 16 степени, т.е. 65536 символов. Вроде бы все неплохо, к тому же окончательная величина кодового пространства в UTF-16 была расширена до более, чем 1 миллиона символов.
Однако и данная кодировка до конца не удовлетворяла потребности разработчиков. Скажем, если вы пишете, используя исключительно латинские символы, то после перехода с расширенной версии кодировки ASCII к UTF-16 вес каждого файла увеличивался вдвое.
В результате, была предпринята еще одна попытка создания чего-то универсального , и этим чем-то стала всем нам известная кодировка UTF-8.
UTF-8 - это многобайтовая кодировка с переменной длинной символа . Глядя на название, можно по аналогии с UTF-32 и UTF-16 подумать, что здесь для кодирования одного символа используется 8 бит, однако это не так. Точнее, не совсем так.
Дело в том, что UTF-8 обеспечивает наилучшую совместимость со старыми системами, использовавшими 8-битные символы. Для кодирования одного символа в UTF-8 реально используется от 1 до 4 байт (гипотетически можно и до 6 байт).
В UTF-8 все латинские символы кодируются 8 битами, как и в кодировке ASCII . Иными словами, базовая часть кодировки ASCII (128 символов) перешла в UTF-8, что позволяет "тратить" на их представление всего 1 байт, сохраняя при этом универсальность кодировки, ради которой все и затевалось.
Итак, если первые 128 символов кодируются 1 байтом, то все остальные символы кодируются уже 2 байтами и более. В частности, каждый символ кириллицы кодируется именно 2 байтами.
Таким образом, мы получили универсальную кодировку, позволяющую охватить все возможные символы, которые требуется отобразить, не "утяжеляя" без необходимости файлы.
C BOM или без BOM?
Если вы работали с текстовыми редакторами (редакторами кода), например Notepad++ , phpDesigner , rapid PHP и т.д., то, вероятно, обращали внимание на то, что при задании кодировки, в которой будет создана страница, можно выбрать, как правило, 3 варианта:
ANSI
- UTF-8
- UTF-8 без BOM

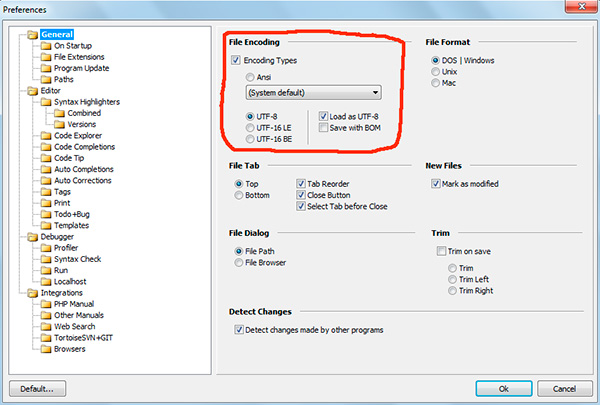
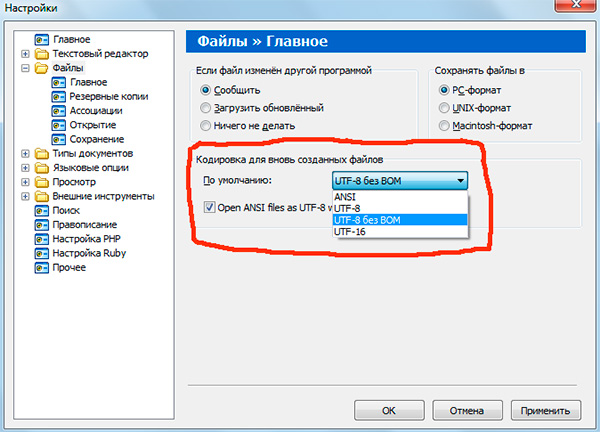
Сразу скажу, что выбирать всегда стоит именно последний вариант - UTF-8 без BOM .
Итак, что же такое BOM и почему нам это не нужно?
BOM расшифровывается как Byte Order Mark . Это специальный Unicode-символ, используемый для индикации порядка байтов текстового файла. По спецификации его использование не является обязательным, однако если BOM используется, то он должен быть установлен в начале текстового файла.
Не будем вдаваться в детали работы BOM . Для нас главный вывод следующий: использование этого служебного символа вместе с UTF-8 мешает программам считывать кодировку нормальным образом , в результате чего возникают ошибки в работе скриптов.
Прежде чем отвечать на вопрос о том, что же такое кодировка ANSI Windows, ответим сначала на другой вопрос: "Что же такое кодировка вообще?"
У каждого компьютера, в каждой системе используется определенный набор символов, зависящий от языка, используемого пользователем, от его профессиональных компетенций и личных предпочтений.
Общее определение кодировки
Так, в русском языке используется 33 символа для обозначения букв, в английском - 26. Также используется 10 цифр для счета (0; 1; 2; 3; 4; 5; 6; 7; 8; 9) и некоторые специальные символы, минус, пробел, точка, процент и так далее.
Каждому из этих символов при помощи кодовой таблицы присваивается порядковый номер. К примеру, букве "A" может быть присвоен номер 1; "Z" - 26 и так далее.
Собственно, номер, представляющий символ как целое число, считается кодом символа, а кодировка - это, соответственно, набор символов в такой таблице.
Богатство разнообразия кодовых таблиц
На данный момент существует довольно большое количество кодировок и кодовых таблиц, используемых разными специалистами: это и ASCII, разработанная в 1963 году в Америке, и Windows-1251, совсем недавно еще бывшая популярной благодаря Microsoft, KOI8-R и Guobiao - и многие, многие другие, причем процесс их появления и отмирания происходит и по сей день.
Среди этого огромного списка совершенно особо держится так называемая кодировка ANSI.
Дело в том, что в свое время компания Microsoft создала целый набор кодовых страниц:
Все они получили общее название таблицы кодировки ANSI, или кодовой страницы ANSI.
Интересный факт: одной из первых кодовых таблиц стала ASCII, в 1963 году созданная American National Standards Institute (Американским национальным институтом стандартов), сокращенно называвшимся именно ANSI.
Помимо всего прочего, эта кодировка содержит и непечатные символы, так называемые "Управляющие последовательности", или ESC, уникальные для всех таблиц символов, зачастую несовместимые между собой. При умелом использовании, однако, они позволяли скрывать и восстанавливать курсор, переводить его с одного положения в тексте на другое, устанавливать табуляцию, стирать часть окна терминала, в котором велась работа, изменять форматирование текста на экране и менять цвет (или даже рисовать и подавать звуковые сигналы!). В 1976 году, кстати, это было довольно неплохим подспорьем для программистов. Кстати, терминал - это устройство, требующееся для ввода и вывода информации. В те далекие времена он представлял собой монитор и клавиатуру, подсоединенные к ЭВМ (электронной вычислительной машине).
Некорректное отображение символов
К сожалению, в дальнейшем подобная система вызвала многочисленные сбои в системах, выводя вместо желаемых стихов, лент новостей или описаний любимых компьютерных игр так называемые кракозябры - бессмысленные, нечитаемые наборы символов. Появление этих вездесущих ошибок было вызвано всего лишь попыткой отображать символы, закодированные в одной кодовой таблице, при помощи другой.

Чаще всего с последствиями неверного чтения этой кодировки мы сталкиваемся в Интернете до сих пор, когда наш браузер по какой-то причине не может достаточно точно определить, какая именно из Windows-**** кодировок используется в данный момент, из-за указания веб-мастером общей кодировки ANSI либо изначально неверной кодировки, к примеру, 1252 вместо 1521. Ниже представлена точная таблица кодировок.
Кириллическая таблица ANSI-кодировок, Windows-1251
Более того, в 1986 году ANSI была существенно расширена, благодаря Яну Э. Дэвису, написавшему пакет The Draw, позволяющий не просто использовать базовые, с нашей точки зрения, функции, но и полноценно (или почти полноценно) рисовать!

Подводя итоги
Таким образом, можно видеть, что кодировка ANSI, по сути, хоть и была довольно спорным решением, сохраняет свои позиции.

Со временем с легкой руки энтузиастов древний терминал ANSI перекочевал даже на телефоны!
Стоит отметить, что все обозначения классов давления по ANSI несут определенный смысл, а именно значение давления, но только в иных единицах, чем мы привыкли. Все цифры после ANSI обозначают значение Условного (Номинального) Давления: ANSI 150, ANSI 300, ANSI 600, ANSI 900, ANSI 1500, ANSI 2500 и ANSI 4500. К примеру, ANSI 150 означает что условное давление 150 фунтов на квадратный дюйм. По-английски это пишется как Pound-force per Square Inch или коротко PSI.
Соответственно, таким образом можно сделать самостоятельный перевод из фунтов на квадратный дюйм в бар (100 кПа) или МПа. Для самостоятельного расчета точного потребуется знать, что 1 PSI = 6894,76 Па. Все расчеты давления ANSI в бар и в Паскали можно делать, когда есть время и необходимость в получении точных данных, в то же время, большинство стандартных значений классов давлений по ANSI уже имеют стандартные значения в бар и МПа. Для упрощения, мы составили короткую таблицу для вашего пользования:
Таблица классов давления ANSI с переводом в Бар и МПа
Класс давления ANSI | ||
|
Код (двоичный) |
(десятичный беззнаковый) |
(десятичный знаковый) |
|
|
А (большое латинское) | |||
|
B (большое латинское) | |||
|
a (малое латинское) | |||
|
А (большое русское) В кодировке ANSI | |||
|
А (большое русское) В кодировке ASCII |
Подобный код, как показано выше, соответствует также целому числу от 0 до 255 в беззнаковом (unsigned) формате. Таким образом, каждому символу соответствует целое число, также называемое кодом символа. Совокупность кодов символов называется кодовой таблицей или кодировкой .
Для персональных компьютеров наиболее распространены кодовые таблицы ANSI (American National Standard Institute) и ASCII (American Standard Code for Information Interchange). Таблица ANSI применяется в Windows, а ASCII применялась в DOS. Однако в этих двух таблицах первые 128 кодов (от 0 до 127) совпадают ; они различаются лишь последующими 128 кодами, используемыми для хранения национальных (русских) букв и символов "псевдографики".
В приведенных таблицах обозначение КС означает "код символа", а С – "символ".
Стандартная часть таблицы символов (ascii-ansi)
Некоторые из вышеперечисленных символов имеют особый смысл. Так, например, символ с кодом 9 обозначает символ горизонтальной табуляции, символ с кодом 10 – символ перевода строки, символ с кодом 13 – символ возврата каретки.
Иногда даже достаточно опытный специалист не сразу скажет вам, чему соответствует то или иное значение давления или длины в одной системе значениям в другой системе величин.
Чтобы облегчить вам эту задачу, мы предлагаем таблицы соотношения величин давления и длины в европейской и американской системах с небольшими пояснениями . Но сначала несколько слов о самих стандартах.
DIN - это немецкий стандарт (расшифровывается как Deutsches Institut für Normung , то есть разработанный Германским институтом стандартизации), который разрабатывается строго в рамках положений Международной организации по стандартизации - ISO (International Organization for Standardization).
ANSI – стандарт, принятый в Соединённых Штатах Америки. Расшифровывается как American National Standards Institute , то есть стандарт Американского национального института по стандартизации.
Соответственно, нормы ANSI определяются именно этим институтом, и далеко не всегда между стандартами DIN и ANSI можно проследить точные соответствия в различных сферах.
Перевод единиц давления из ANSI в DIN
Здесь всё просто: если по стандарту ANSI напротив давления стоит цифра 150 - это означает, что номинальное (на которое рассчитана арматура) давление составляет 20 бар, 300 - 50 бар и т.д. Максимальное значение по ANSI Class – 2500 будет равно 420 бар по европейскому стандарту DIN .
Пользуясь этой таблицей, несложно переводить значения давления и обратно: из DIN в ANSI , хотя осуществлять такой перевод нашим инженерам требуется гораздо реже .
Перевод единиц длины из американской системы в европейскую (российскую)
Как известно, американцы всё измеряют дюймами и футами, а мы и европейцы - миллиметрами, сантиметрами и метрами, то есть, как и подавляющее большинство государств мира, мы живём в метрической системе единиц.
Как же переводить дюймы в миллиметры? На самом деле, в этом также нет ничего сложного, достаточно лишь запомнить, что 1 дюйм равняется 25,4 мм. Однако нередко цифрой после запятой пренебрегают и для ровного счёта указывают, что 1 дюйм = 25 мм .
Таким образом, если, например, сечение входного отверстия равно 2 дюймам по американской системе мер, то, переведя по вышеуказанному правилу это значение в нашу систему мер, получаем 50 мм или, что более точно - 51 мм (округлив 50,8 по правилам).
Осталось добавить, что диаметр в технических характеристиках маркируется латинскими буквами DN и нередко указывается именно в дюймах , а давление обозначается при помощи букв PN и указывается чаще всего в барах - во всяком случае, мы используем именно такую маркировку как наиболее удобную .
А следующая таблица поможет вам высчитать не только точное количество миллиметров в одном дюйме (с точностью до тысячной миллиметра), но и поможет узнать, сколько миллиметров содержится, например, в 2,5 дюймах.
Для этого находим колонку 2"" (2 дюйма), а слева ищем значение 1/2. Итого 2,5 дюйма = 63,501 мм, что вполне можно округлить до 64 мм, а, например, 6,25 дюйма (то есть 6 и 1/4) = 158,753 мм или 159 мм.
|
| Дюймы "" в миллиметрах |
|||||||
|
| ||||||||
|
| ||||||||
 магнитола в машине хотя питание на ней есть Не работает автомагнитола в машине")

